项目为什么要混合多种语言?一次编译、解释、JIT、AOT的探索之旅
前言
最近深感学习不足,却缺乏动力,于是另辟蹊径,决定进行一些探索性学习 -- 先确定目标,再细化研究,也算是以兴趣驱动了。
作为后端开发,在语言层次之上,深感各种框架层出不穷,它们是设计与实现上的堆叠,甚至会有很多相似设计。
而对于语言层次之下,编译后的代码到底是如何被 OS 进行执行,JVM又是如何执行字节码代码块,接近低层的概念,我几乎一无所知。
在此之上,我决定了文章的标题,本文将预计将按照以下大部分学习讲解(笔者大概会一边查资料、一边实践代码、一边完成此篇文章),探索路线如下:
- 编译型语言混合
- 解释型语言混合
- 解释型语言原理:实现一个简易解释器
- JIT与AOT:JIT主要应用与解释型语言的动态优化技术,而AOT是静态优化技术,Java Native Image 即通过AOT将字节码直接编译为了可执行程序。
- 统一 IR 的运行时生态: WASM,JVM):不同语言编译为同一个中间表示,再在统一的运行时里执行。
灵感及部分插图来源:
【为什么有些项目会使用多种编程语言?】https://www.bilibili.com/video/BV1aXbXzfEsM?vd_source=5c84368f731f642fd424bf08477f0db7
【Why Some Projects Use Multiple Programming Languages】https://www.youtube.com/watch?v=XJC5WB2Bwrc
以上视频讲解了一个项目是如何混合多语言进行编程,对于细节和实现进行了介绍
【深入理解JVM - 虚拟机执行子系统(类结构章节)】
讲解了类的基本结构,由此我了解字节码指令在方法表中是如何存储,字节码执行引擎具体实现我没有去了解,不过我准备在AI指导下快速实现一个简易功能的执行引擎。
如何理解语言混合
如何去理解混合语言呢?
最简单的一个例子:前后端分离开发
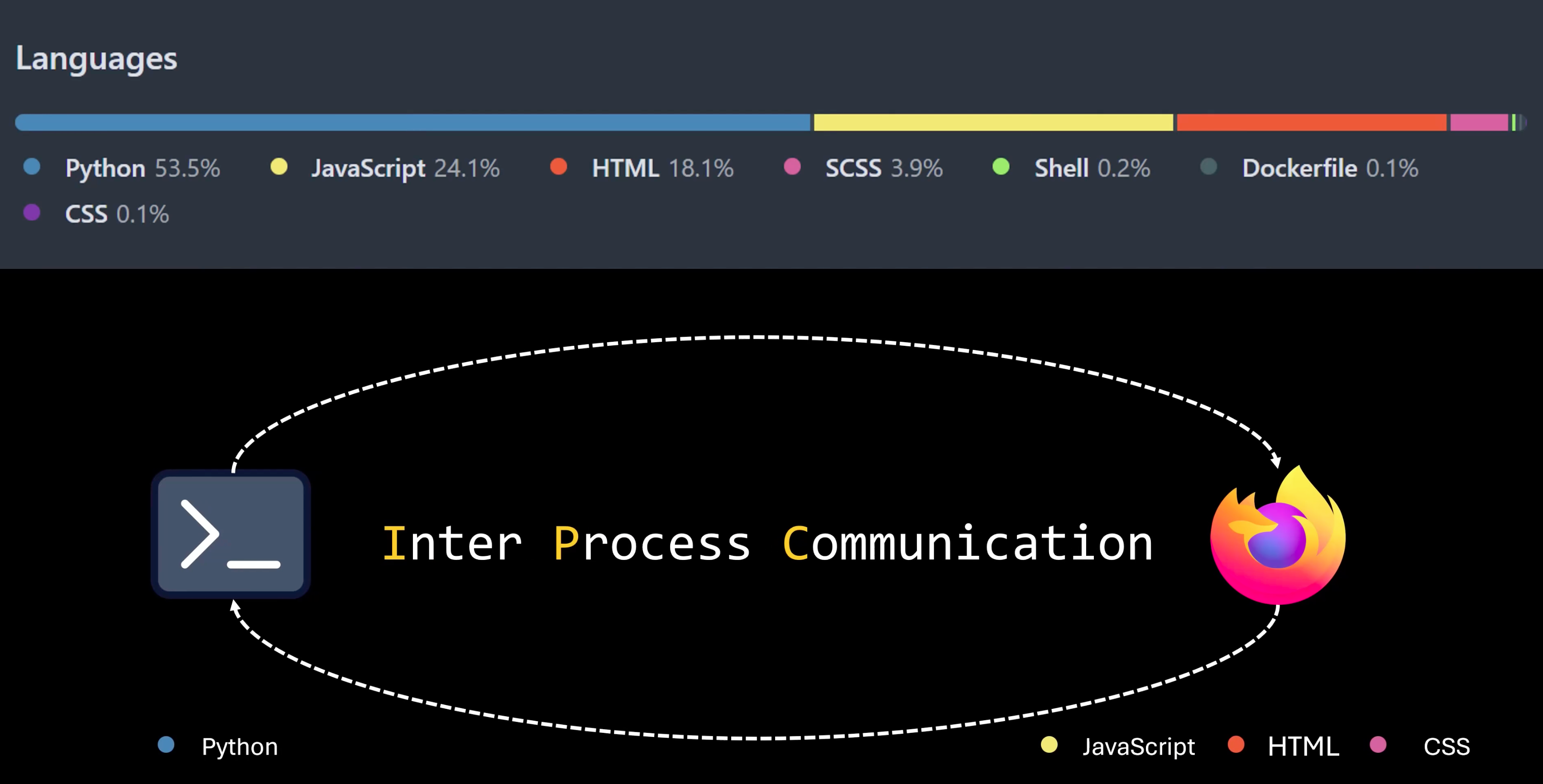
在这里 Python 基于Web框架,提供了HTTP接口;HTML + JavaScript + CSS 构成了一个前段页面,并通过HTTP接口来获取渲染页面数据。
在这里,实际存在了两个进程,它们之间通过进程间通信,来实现数据交互。
这种的并不难理解,但是我们接下来要说的,分析的是另一种形式:使用不同语言编写的项目组件,作为单一进程共同运行。

编译型语言混合
我们先来确认下对于这个问题的探究提纲吧~
示例:C + Rust + Go + 汇编 的混合编译
多个编译型语言如何一起协作?各个语言的运行时管理机制如何处理?
静态编译 + 链接的原理分析与实践
编译的步骤:C语言如何处理 预编译 -> 汇编 -> 编译 -> 链接(静态 + 动态(依赖变更,其他编译后的程序不需要改动)(动态链接的原理?装载内存后,不同应用是否公用?这个原理是什么?是否与JIT相关?))
如何将某个语言构建为依赖库,在另一个语言动态链接
语言混合开发,如何遵守ABI规范? 基于各个语言相关的外部函数关键字吗?
原理:从源代码到可执行程序
编译流程:以C语言为例
Pre-Processor 预处理:注释删除,展开宏定义(解析#include,将目标头文件代码插入到文件中),处理条件编译(#ifdef等)等操作
生成结果:被处理过后的C代码,可读.
Compiler 编译:将处理过后的代码转译为汇编语言
生成结果:汇编语言,可读。
Assembler 汇编:将汇编代码翻译为机器码(01指令)
生成结果:目标文件,但仍无法运行,需要确认二进制文件中的具体位置及其各函数的位置。
Linker 链接:在此阶段,我们可能会存在多个目标文件,部分来自项目的代码,其他则来自开发时引入的外部库。
// stdio.h 是C语言标准库头文件,他的实现代码也需要被处理为目标文件 stdio.o #include<stdio.h> int main() { printf("Hello World"); return 0; }将所有目标文件整合起来,即可得到最终的独立可执行文件。
生成结果:独立可执行的文件。
实现方式
静态链接:从库中提取每个所需函数的机器码,将其复制到最终的可执行文件。
动态链接:将函数库预编译为 动态共享库(UNIX中.so文件,Windows中.dll文件),它们都包含函数库所提供的可执行函数代码,但不包含启动执行的入口点。在此种编译情况下,连接器会在最终只插入对该库引用,而库存储了该函数的机器指令。
在运行时,进行加载动态共享库,在程序中动态计算真实内存地址(这里我比较好奇,DeepSeek告知这种动态计算逻辑是链接器添加到了可执行文件的同步,在程序启动时,发生一次计算),不同进行可以共用内存中的同一个共享库文件代码。
可以通过命令将GCC执行各个步骤文件显示
gcc_test % gcc main.c -o main -save-temps
gcc_test % ls
main main.bc main.c main.i main.o main.s
# main.c 源文件
# Pre-Processor -> main.i 预处理后文件
# Complier -> main.s 汇编文件
# Assembler -> main.o 机器码
# Linker -> main 可执行文件
# main.bc 是GCC在编译过程中生成的LLVM字节码文件(Bitcode), 类似于汇编的一种中间表示文件, 目标用于链接优化或跨平台编译, 我在MacOS下使用clang产生, 可以忽略编译阶段化意味着什么?
从上文我们可以得知,编译事实上是由很多不同的阶段组成的。
通过GCC指令我们可以让其在某个阶段进行停止,例如下方示例,在生成汇编代码后停止。在某些场景下,可以进行审查关键代码的性能。
gcc_test % gcc main.c -S
gcc_test % ls
main.c main.s我们也可以直接将汇编代码交给GCC去构建可执行文件
gcc_test % gcc main.s -o main
gcc_test % ls
main main.c main.s这意味着我们可以直接编写一个汇编代码,在不同阶段来最终交给编译器进行处理,最终交由链接器去处理为一个可执行文件。
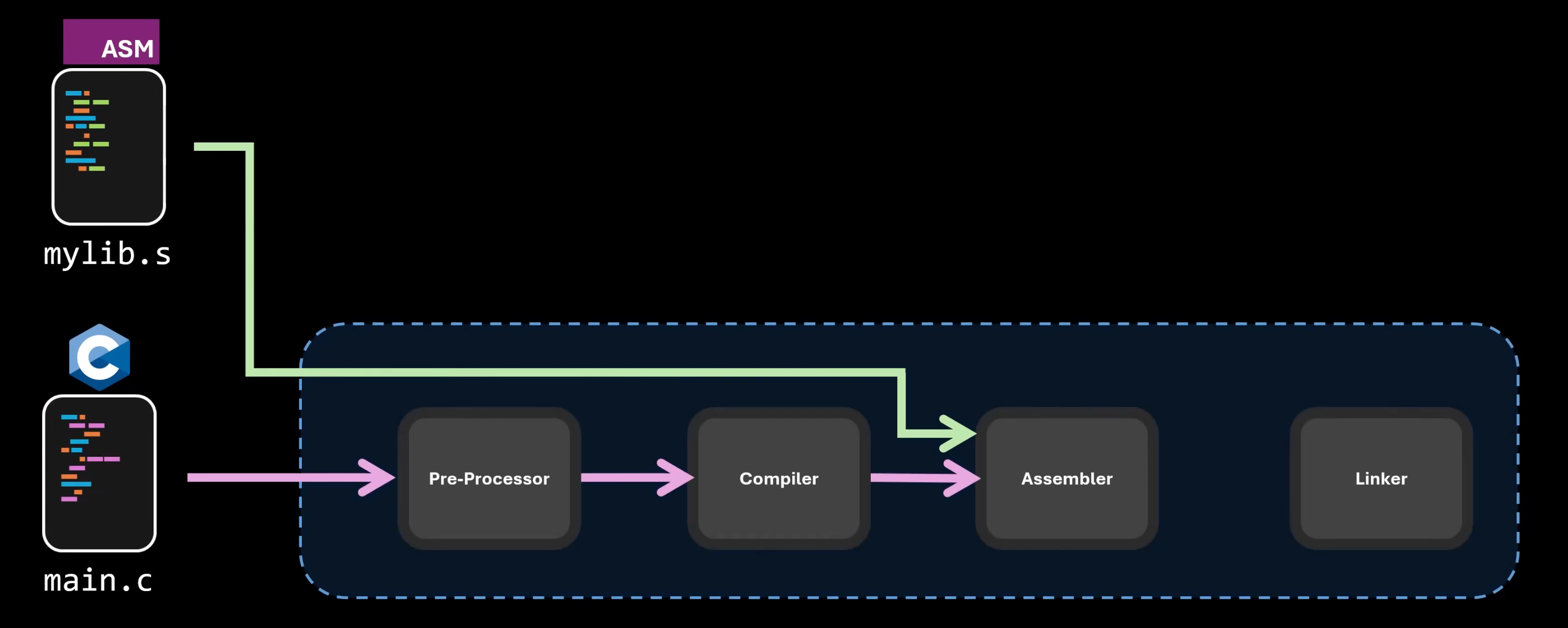
在这个过程中,我们实际上已经混合了两种不同的语言:汇编语言、C语言,例如大名鼎鼎的 FFmpeg,今年我还有看到文章,某个贡献者直接编写汇编代码将某个函数性能带来了巨量的提升。
由此我们也可以窥探到,其实不同编译型语言的混合,也是基于此,它们在编写后,最终只需要通过编译器处理链接在一起即可,而一个进程的不同模块、功能的实现,可以有更多的语言选择,开发者可以基于相关语言的生态或者性能进行择优选择。
什么是GCC
GCC全称为 GNU Compiler Collection,是一组按顺序执行的工具执行链,每个工具都接受上一个工具的输出作为输入,并产生自己的输出,且工具都是可插拔的, 我们可以对其进行替换,或者在中间阶段注入我们自己的文件。
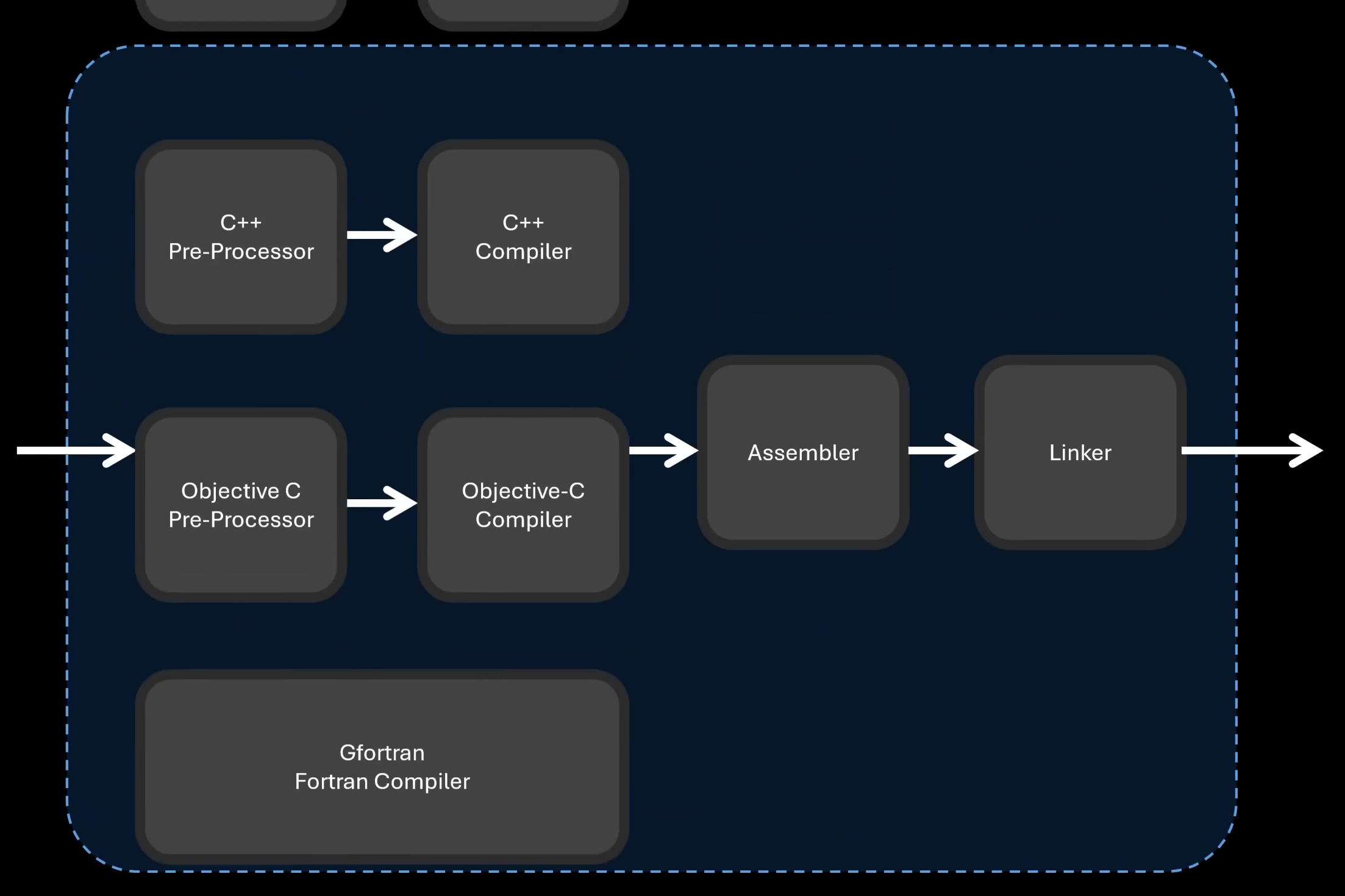
基于配置项,它可支持很多种语言
The GNU Compiler Collection includes front ends for C, C++, Objective-C, Fortran, Ada, Go, D, Modula-2, and COBOL as well as libraries for these languages (libstdc++,...).
GNU 也是一段故事,其全称为 GNU's Not Unix,其全称是个可递归的名字,这个项目开发了很多关键组件,如 GCC,是因当时闭源商业化的UNIX系统而引发的项目。
高级语言混合开发
在上面的描述中,我们看到了编译的不同阶段,我们通过控制不同阶段的编译器功能执行,甚至可以做到汇编语言和C语言程序的混合编译。
汇编语言终归是编译步骤中的一环,更多是基于生态与特性去选取高级语言进行混合开发。
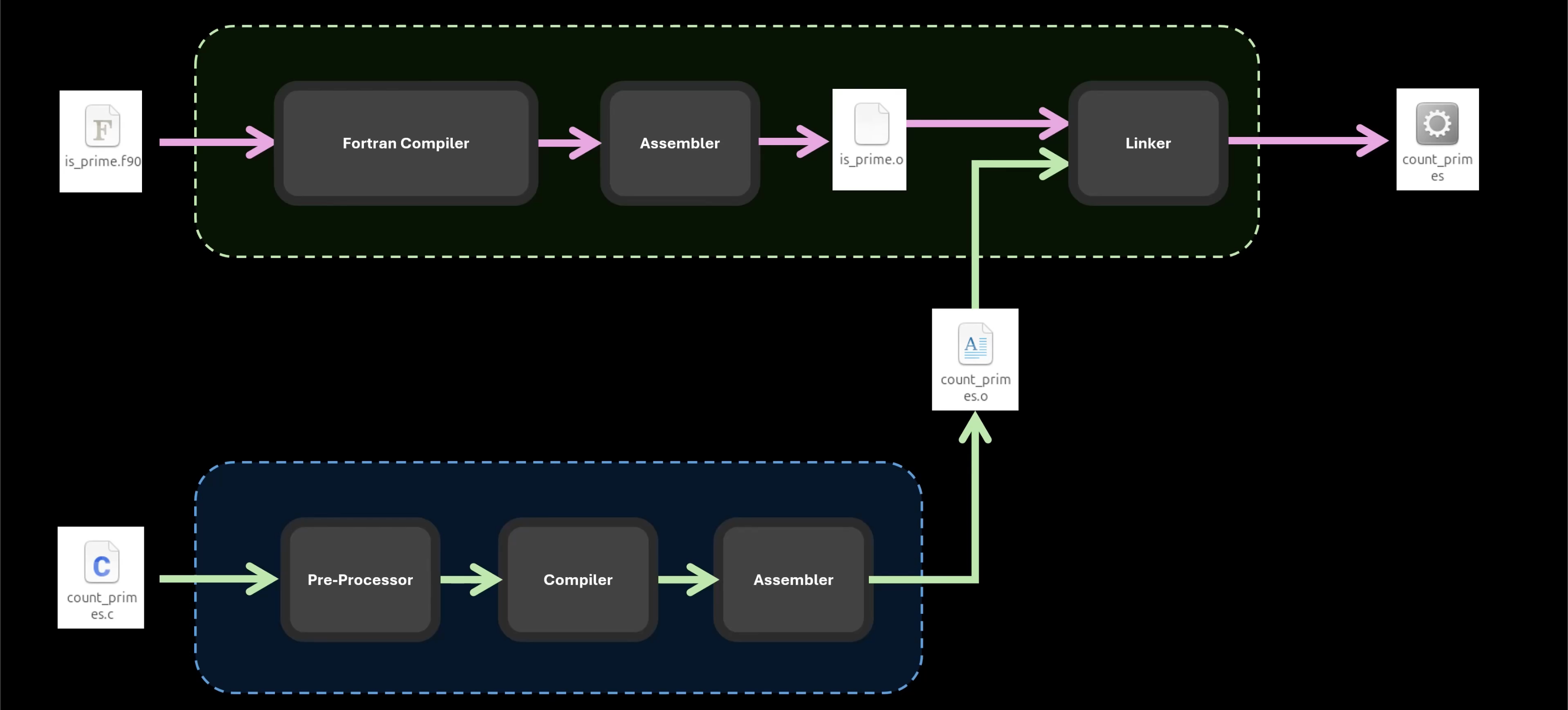
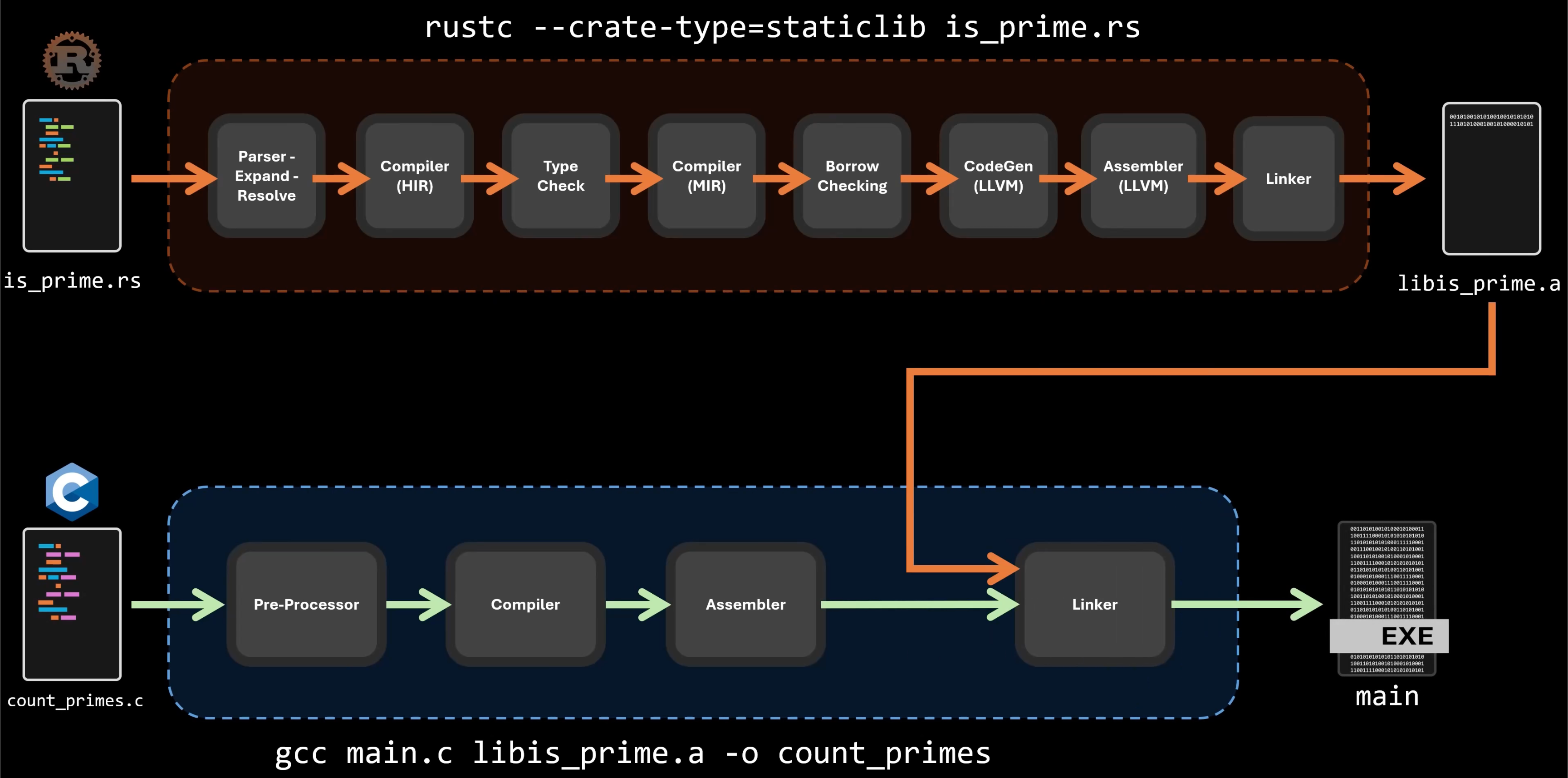
其关键点实际在于最终 链接 步骤,Linker 是实现的关键。
不同语言混合开发的连接点事实上是目标文件(.o),此时文件内已经为机器码和符号表。
此时再用同一个 Linker 链接成为同一个二进制文件即可。
混合语言的关键:ABI
不同语言编译器在编译阶段对一些底层细节的处理方式是不同的,比如函数调用约定、符号命名规则、内存对齐方式、返回值处理方式等实现差异。这些差异会直接影响目标文件中机器码与符号表的生成方式。那么不同语言目标文件链接在一起,会导致其代码执行存在偏差异常。ABI 是解决此问题的答案。
什么是 ABI Application Binary Interface,应用二进制接口。它在多语言混合开发中非常关键,它保证了不同编译器(甚至不同语言)生成的代码能够通过同一个 Linker 进行链接。
ABI 规范了以下核心内容:
- 函数调用约定:参数传递(寄存器传递、栈传递);返回值处理;栈清理
- 符号命名约定:不同编译器与语言采用不同的符号命名规则
- 数据结构内存布局:不同语言对结构体、类、枚举的内存对齐、布局可能不同,需要确保内存布局一致
- 系统调用和标准库接口:保证系统调用或标准库函数在不同语言中的一致性,确保程序在不同语言间交互时不出问题。
Linker 不关心源代码是由哪种语言编写,它只关心目标文件中已经处理好的机器码和符号。
目标文件中内部包含了编译器生成的机器码与符号表,这些符号信息与实际机器码通过ABI进行对接,保证了不同语言间的无缝链接。
其实我很纠结应该到哪种细致程度,关于 ABI 机制,我很想了解到 Linker 到底是如何基于 ABI 进行链接,什么原理,如何检测到 ABI 是否符合。
但是从专业领域和文章目的来讲,深究有点超出我目前的能力与文章的目的了,以上内容也是基于 ChatGPT 创作,感兴趣大家自行多多了解吧。
实验:多种编译型语言开发
环境搭建
采用 Dockerfile 直接构建一个 Rust + C + 汇编的开发编译环境
FROM rust:1.81
# 替换为阿里云 Debian 源
RUN rm -f /etc/apt/sources.list.d/debian.sources && \
echo "deb http://mirrors.aliyun.com/debian bookworm main contrib non-free non-free-firmware" > /etc/apt/sources.list && \
echo "deb http://mirrors.aliyun.com/debian bookworm-updates main contrib non-free non-free-firmware" >> /etc/apt/sources.list && \
echo "deb http://mirrors.aliyun.com/debian-security bookworm-security main contrib non-free non-free-firmware" >> /etc/apt/sources.list && \
apt update && apt install -y build-essential nasm
gcc -c cfunc.c -o cfunc.o
WORKDIR /app
COPY . /app
CMD ["bash"]打包
docker build -t rust-mix .执行
# 建议先把下方源码环境搭建,再通过挂在方式将目标文件映射进行,因为当前镜像没安装vi/vim
docker run -it --rm -v ./mix_demo:/app/mix_demo rust-mix源码
构建一个 Rust 项目,通过 Cargo Build.rs 来将 C / ASM 编译为目标文件,再通过 rustc 链接 Rust 标准库后生成可执行文件。
cargo new mix_demo文件目录
mix_demo
├── build.rs
├── Cargo.lock
├── Cargo.toml
└── src
├── asmfunc.s
├── cfunc.c
└── main.rs
2 directories, 6 filesbuild.rs
fn main() {
cc::Build::new()
.file("src/cfunc.c")
.file("src/asmfunc.s")
.compile("mix_lib");
}Cargo.toml
[package]
name = "mix_demo"
version = "0.1.0"
edition = "2021"
[build-dependencies]
cc = "1.0"main.rs
extern "C" {
fn c_add(a: i32, b: i32) -> i32;
fn asm_mul(a: i64, b: i64) -> i64;
}
fn main() {
let a = 6i32;
let b = 7i32;
unsafe {
let sum = c_add(a, b);
let product = asm_mul(a as i64, b as i64);
println!("C result: {}", sum);
println!("ASM result: {}", product);
}
}cfunc.c
int c_add(int a, int b) {
return a + b;
}asmfunc.s
.global asm_mul
asm_mul:
mul x0, x0, x1
ret执行结果
root@xxxxxx:/app/mix_demo# cargo run
Compiling shlex v1.3.0
Compiling find-msvc-tools v0.1.4
Compiling cc v1.2.41
Compiling mix_demo v0.1.0 (/app/mix_demo)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.96s
Running `target/debug/mix_demo`
C result: 13
ASM result: 42总结
经过上方的过程,我们了解了语言编译的过程,以及项目是如何进行混合开发,混合编译到同一个执行程序之中。
其实还有很多细节没有深挖,如:
- 混合编译的情况下,像是 Go 这种自带垃圾回收机制的语言,其程序是如何处理的呢?
- Linker 在链接过程之中,到底检查了什么,如何检查并链接的呢?
- ABI 机制如何在目标文件中体现出来
不过就到此为止吧。
解释型语言的混合
解释型语言混合的示例就很好做啦,我们来试一下 Java + Kotlin 吧。
JVM 是以字节码为基础进行执行的,混合开发其实不难理解,无论上层是什么,最终只要符合字节码规范即可。
而且不同语言垃圾回收机制是在 JVM 层进行保证,不涉及不同语言的运行时问题。
源码
文件目录
~/mix_demo
├── build
│ └── reports
│ └── problems
│ └── problems-report.html
├── build.gradle.kts
├── gradle
│ └── wrapper
│ ├── gradle-wrapper.jar
│ └── gradle-wrapper.properties
├── gradlew
├── gradlew.bat
├── settings.gradle.kts
└── src
├── main
│ ├── java
│ │ ├── KotlinFunc.kt
│ │ └── Main.java
│ └── resources
└── test
├── java
└── resources
13 directories, 9 filesbuild.gradle.kts
plugins {
kotlin("jvm") version "1.9.0" // Kotlin 插件,确保使用的是最新版本
application
}
repositories {
mavenCentral() // 使用 Maven 中央仓库
}
dependencies {
implementation(kotlin("stdlib")) // Kotlin 标准库
}
kotlin {
jvmToolchain(8)
}
application {
mainClass.set("Main") // Kotlin 入口类
}Main
/**
* Main
* description: Main
* date 2025/10/16
* @author yancy0109
*/
public class Main {
public static void main(String[] args) {
System.out.println("Hello World! From Java");
System.out.println(new KotlinFunc().greet("Java"));
}
}KotlinFunc
/**
* KotlinFunc
* description: KotlinFunc
* date 2025/10/16
* @author yancy0109
*/
class KotlinFunc {
fun greet(name: String): String {
return "Hello String from Kotlin, Invoker: $name"
}
}执行结果
./gradlew run
> Task :run
Hello World! From Java
Hello String from Kotlin, Invoker: Java
.......解释型语言原理:实现一个解释器
你是否好奇过,解释型语言是如何实现的?例如,JVM是如何通过字节码构建一个与平台无关的执行环境?在《深入理解JVM》中,我们可以了解到,JVM本质上是一个虚拟机,它使用字节码指令来执行程序,而这些字节码指令的结构和机器码指令有些相似,但它们并不直接与硬件交互,而是通过JVM进行执行。这种机制让JVM在不同平台上具有高度的可移植性。JVM的字节码并不总是完全解释执行,随着JIT(即时编译)的加入,JVM可以将字节码在运行时编译为机器码,从而提升性能。
我非常好奇如何通过实现一个简单的解释器来理解这一过程,让我们动手实现一个简单的解释器来理解这一个过程吧。目标包括:
- 实现一个类字节码的执行引擎
- 面向对象
- 基于引用计数的垃圾回收机制
- 支持简单语法:单层 IF-ELSE,FOR循环
过渡问题:那么,为什么有时解释器会比预编译的代码执行得更快呢?(这就引出了JIT技术,它如何帮助解释型语言突破性能瓶颈。)
动态优化技术(JIT & AOT)
解释器如何在运行时生成机器码
- JIT 的作用:热点优化、内联缓存
- AOT 的对比:预编译、启动快、优化受限
- 示例:JVM、.NET、PyPy 的 JIT vs GraalVM AOT
统一 IR 的运行时生态
- JVM、.NET CLR:多语言 → 字节码 → 同一运行时
- WASM:多语言 → WASM IR → 浏览器 / 独立运行时
- 总结:为什么我们能把 Python、Java、Scala 混合?答案就是 统一 IR 提供的共享运行时